쿠버네티스(Kubernetes) 환경에서 안정적인 서비스를 운영하기 위해서는 파드(Pod)의 상태를 정확히 체크하고, 수많은 리소스를 효율적으로 분류하는 능력이 필수적입니다. 오늘은 실무에서 가장 빈번하게 사용되는 **세 가지 프로브(Liveness, Readiness, Startup)**와 리소스 관리의 기본인 **레이블(Labels) & 셀렉터(Selector)**에 대해 알아보겠습니다.
이전시간에 학습한 Ubuntu 기반 Kubernetes kubeadm 설치 가이드 (containerd + Cilium) 바로가기
1. 쿠버네티스의 3가지 상태 확인 메커니즘 (Probes)
쿠버네티스는 컨테이너가 정상인지, 트래픽을 받을 준비가 되었는지를 판단하기 위해 '프로브'라는 헬스체크 기능을 제공합니다.
① Liveness Probe (생존 여부 확인)
- 역할: 컨테이너가 살아있는지 확인합니다.
- 동작: 실패 시 쿠버네티스는 해당 컨테이너를 **재시작(Restart)**합니다. 애플리케이션이 데드락(Deadlock)에 빠졌을 때 유용합니다.
② Readiness Probe (준비 여부 확인)
- 역할: 컨테이너가 서비스 트래픽을 받을 준비가 되었는지 확인합니다.
- 동작: 실패 시 해당 파드를 서비스 엔드포인트에서 제외합니다. 설정 파일 로딩이나 데이터베이스 연결 대기 중에 사용합니다.
③ Startup Probe (기동 여부 확인)
- 역할: 애플리케이션이 최초로 실행되는 중인지 확인합니다.
- 동작: 성공할 때까지 다른 프로브(Liveness, Readiness)를 비활성화합니다. 기동 시간이 매우 긴 '무거운' 애플리케이션에 필수적입니다.
2. YAML 작성 방법 및 주요 설정 옵션
실제 사용할 수 있는 통합 YAML 예제와 상세 설정값입니다.

YAML 예제 (deployment.yaml)
apiVersion: apps/v1
kind: Deployment
metadata:
name: probe-demo
spec:
replicas: 3
selector:
matchLabels:
app: ex-system
template:
metadata:
labels:
app: ex-system
spec:
containers:
- name: main-app
image: my-app:latest
ports:
- containerPort: 8080
# 1. 스타트업 프로브: 최초 기동 시 30초 대기
startupProbe:
httpGet:
path: /healthz
port: 8080
failureThreshold: 30
periodSeconds: 1
# 2. 라이브니스 프로브: 런타임 중 교착 상태 감지
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 5
periodSeconds: 10
# 3. 레디니스 프로브: 트래픽 투입 가능 여부 판단
readinessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 5
periodSeconds: 5상세 설정 가이드 (Parameters)
- initialDelaySeconds: 컨테이너 시작 후 프로브를 시작하기 전까지의 대기 시간(초).
- periodSeconds: 프로브를 수행하는 빈도(초).
- timeoutSeconds: 결과 대기 시간. 응답이 이 시간보다 늦으면 실패로 간주.
- successThreshold / failureThreshold: 몇 번 성공/실패해야 최종 상태를 변경할지 결정.
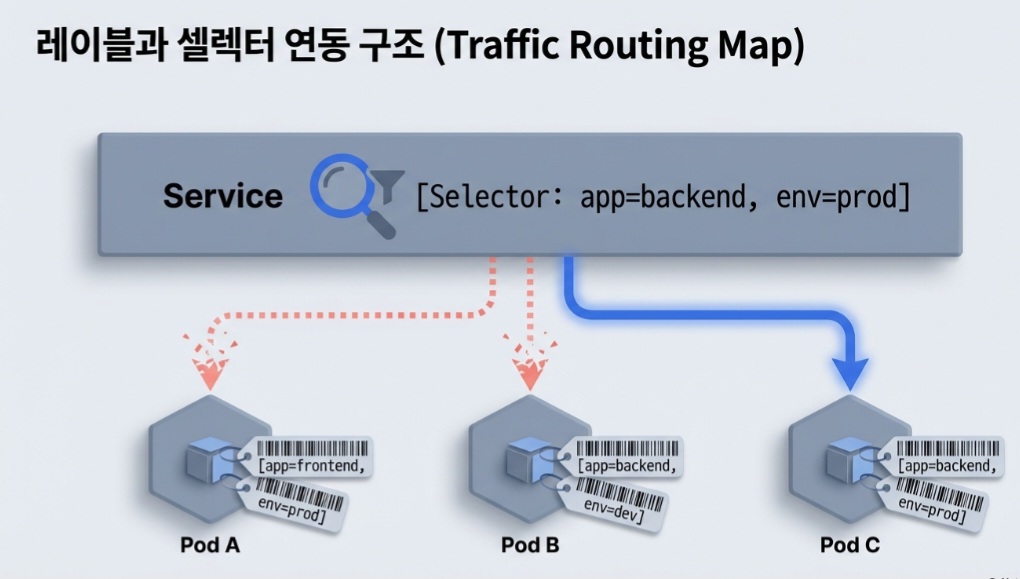
3. 리소스 분류 방법: 레이블(Labels)과 셀렉터(Selector)
쿠버네티스의 철학은 '이름'이 아닌 '레이블(Label)'로 리소스를 관리하는 것입니다.
레이블 (Labels)
파드나 노드 등 객체에 붙이는 key-value 쌍입니다. (예: env: prod, tier: backend)
셀렉터 (Selector)
레이블을 이용해 특정 리소스 그룹을 필터링합니다.
- Equality-based: app == my-app
- Set-based: env in (prod, dev)
4. 수행 및 테스트 예시
실제로 프로브가 어떻게 작동하는지 터미널에서 확인하는 방법입니다.
테스트 1: 이벤트 로그 확인
파드가 재시작되거나 트래픽에서 빠지는 경우, 가장 먼저 아래 명령어로 이벤트를 확인해야 합니다.
kubectl describe pod [POD_NAME]
- 결과 예시: Liveness probe failed: HTTP probe failed with statuscode: 500
테스트 2: Readiness 상태 확인
파드가 Running 상태임에도 READY 컬럼이 0/1이라면 레디니스 프로브가 실패한 것입니다.
kubectl get pods
# NAME READY STATUS RESTARTS
# probe-demo 0/1 Running 0
5. 구조적 아키텍처
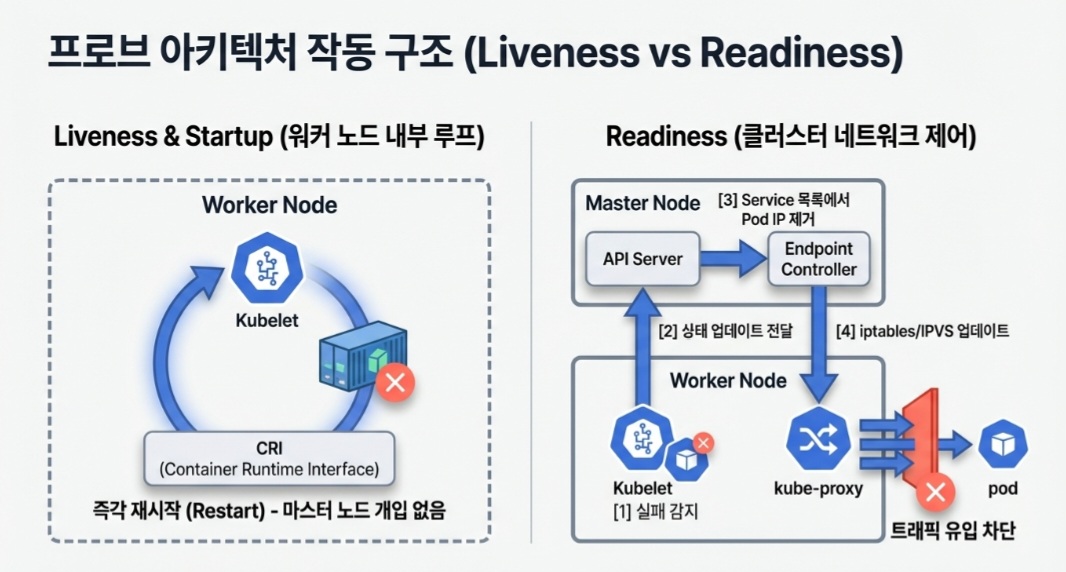
1. Kubelet과 프로브의 실행 메커니즘
모든 프로브의 실행 주체는 각 워커 노드(Worker Node)에 상주하는 Kubelet입니다. Kubelet은 파드 스펙(Pod Spec)에 정의된 메커니즘에 따라 컨테이너의 상태를 직접 확인합니다.
상태 확인 방식
- HTTPGet: 지정된 포트와 경로로 HTTP GET 요청을 보냅니다.
- TCPSocket: 지정된 포트로 TCP 연결을 시도합니다.
- Exec: 컨테이너 내부에서 특정 명령을 실행하고 종료 코드를 확인합니다.
- GRPC: gRPC를 통한 상태 확인을 수행합니다.
Liveness 및 Startup Probe의 동작
Liveness와 Startup 프로브는 해당 노드 내에서 Kubelet이 독립적으로 의사결정을 내립니다.
- 프로브가 실패 조건에 도달하면 Kubelet은 즉시 컨테이너 런타임 인터페이스(CRI)를 통해 해당 컨테이너를 중지시키고, 파드의 재시작 정책(restartPolicy)에 따라 새로운 컨테이너를 생성합니다.
- 이 과정은 마스터 노드의 개입 없이 해당 노드 레벨에서 즉각적으로 처리됩니다.
2. Readiness Probe와 서비스 엔드포인트 제어
Readiness Probe는 컨테이너의 재시작이 아닌 네트워크 트래픽 유입 여부를 결정합니다. 이는 클러스터 전체의 네트워킹 컴포넌트와 연동되어 동작합니다.
제어 흐름 및 컴포넌트 통신
- 상태 업데이트: Kubelet이 레디니스 프로브 실패를 감지하면 해당 정보를 API 서버에 전달합니다.
- 엔드포인트 컨트롤러(Endpoint Controller): 마스터 노드의 컨트롤러 매니저 내에 있는 엔드포인트 컨트롤러는 API 서버를 모니터링하다가 파드의 Ready 상태가 False로 변경되면, 해당 파드의 IP를 서비스의 엔드포인트 목록에서 제거합니다.
- Kube-proxy 업데이트: 변경된 엔드포인트 정보는 각 워커 노드의 kube-proxy로 전달됩니다.
- 트래픽 차단: kube-proxy는 iptables 또는 IPVS 규칙을 업데이트하여 해당 파드로 트래픽이 전달되지 않도록 경로를 수정합니다.
'DevOps > Kubernetes' 카테고리의 다른 글
| [Kubernetes] ReplicaSet과 Deployment, 대체 뭐가 다른 걸까? (차이점 명확히 알기) (1) | 2026.03.11 |
|---|---|
| [Kubernetes] Pod의 생명주기(Lifecycle)와 리스타트 정책(Restart Policy) 완벽 이해 (0) | 2026.03.09 |
| [Kubernetes] 쿠버네티스 Deployment 완벽 정리: 중단 없는 서비스 배포의 핵심 (0) | 2026.03.06 |
| [Kubernetes] Kubernetes ReplicaSet과 Replicas 완벽 이해하기 (0) | 2026.03.04 |
| Ubuntu 기반 Kubernetes kubeadm 설치 가이드 (containerd + Cilium) (0) | 2026.02.18 |



댓글