오늘은 쿠버네티스 네트워킹의 핵심 중 하나인 "Pod 간 통신 (Pod-to-Pod Communication)"에 대해 알아보겠습니다.
쿠버네티스는 마이크로서비스 아키텍처를 기반으로 설계되었으며, 수많은 Pod들이 서로 협력하여 전체 애플리케이션을 구성합니다. 따라서 Pod들이 어떻게 서로를 찾고 통신하는지 이해하는 것은 쿠버네티스를 효율적으로 활용하고 문제를 해결하는 데 필수적입니다.
이전에 학습한 [kubernetes] 쿠버네티스의 핵심 구성요소 완벽 이해: kube-system, api-server, etcd 알아보기
쿠버네티스 네트워킹의 특징: 플랫 네트워킹
쿠버네티스는 모든 Pod들이 고유한 IP 주소를 가지는 플랫 네트워킹 (Flat Networking) 모델을 지향합니다. 즉, 각 Pod는 다른 Pod와 통신할 때 NAT (Network Address Translation) 없이 직접 IP 주소를 사용하여 통신할 수 있습니다. 마치 모든 Pod들이 하나의 커다란 로컬 네트워크에 연결되어 있는 것과 같습니다.
이러한 플랫 네트워킹 모델은 다음과 같은 장점을 제공합니다.
- 간단한 통신: NAT로 인한 복잡성을 줄이고, Pod들이 서로를 직접 인지하고 통신할 수 있도록 합니다.
- 서비스 디스커버리: Pod의 IP 주소를 알고 있다면 다른 Pod를 쉽게 찾을 수 있습니다.
- 네트워크 정책: 네트워크 정책을 통해 Pod 간 통신을 세밀하게 제어할 수 있습니다.
Pod 간 통신 동작 과정
그렇다면 실제로 Pod들이 어떻게 서로 통신할까요? Pod 간 통신은 크게 세 가지 경우로 나눌 수 있습니다.
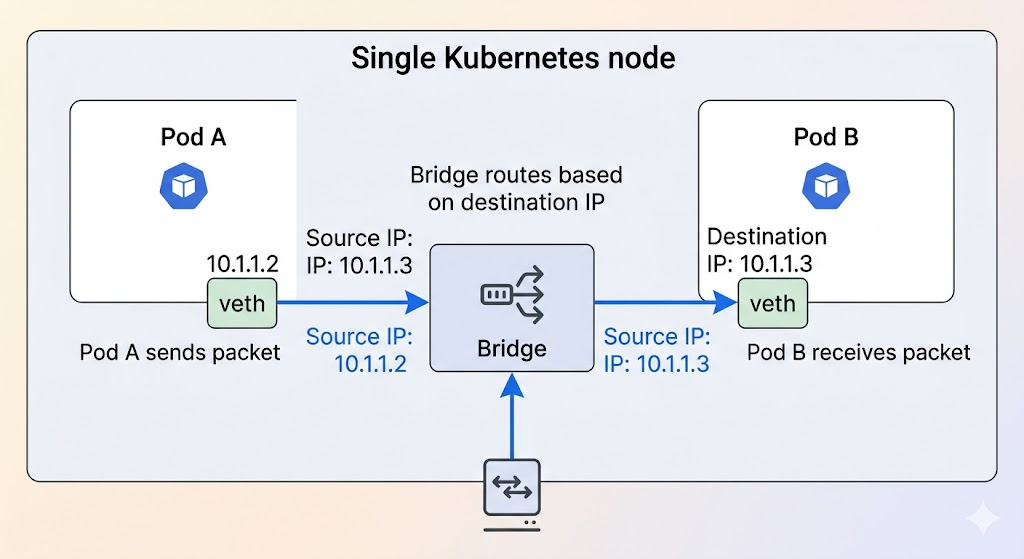
1. 동일 Node 내 Pod 간 통신
가장 간단한 경우입니다. 두 Pod가 동일한 Node에 위치할 때, 이들은 Node 내부의 브리지 (Bridge)를 통해 직접 통신합니다.
작동 방식:
- Pod A가 Pod B의 IP 주소로 패킷을 전송합니다.
- 패킷은 Pod A의 네트워크 인터페이스 (veth)를 통해 Node의 브리지로 전달됩니다.
- 브리지는 패킷의 목적지 IP 주소를 확인하고, 해당 IP 주소를 가진 Pod B의 네트워크 인터페이스 (veth)로 패킷을 전달합니다.
- Pod B는 패킷을 수신합니다.
이 과정은 Node 내부에서 로컬로 처리되므로 매우 빠르고 효율적입니다.
2. 서로 다른 Node 간 Pod 통신 (CNI 플러그인 활용)
대부분의 경우 Pod들은 서로 다른 Node에 분산되어 배치됩니다. 이 경우 통신은 좀 더 복잡해지며, CNI (Container Network Interface) 플러그인의 역할이 중요해집니다.
쿠버네티스는 자체적으로 Pod 간 네트워크를 구축하지 않고, CNI 플러그인 규격을 통해 다양한 네트워크 솔루션을 사용할 수 있도록 지원합니다. 대표적인 CNI 플러그인으로는 Calico, Flannel, Cilium 등이 있습니다.
작동 방식 (Calico 예시):
- Pod A (Node 1)가 Pod B (Node 2)의 IP 주소로 패킷을 전송합니다.
- 패킷은 Node 1의 브리지를 거쳐 Node 1의 라우팅 테이블로 전달됩니다.
- 라우팅 테이블은 목적지 IP 주소 (Pod B의 IP)가 다른 Node (Node 2)에 위치함을 확인합니다.
- 이때 Calico와 같은 CNI 플러그인은 터널링 (Tunneling) 기술을 사용하여 패킷을 캡슐화 (Encapsulation)합니다. 예를 들어, 원래 패킷을 VXLAN 패킷 안에 담아 송신 Node (Node 1)의 물리 IP 주소에서 수신 Node (Node 2)의 물리 IP 주소로 전송합니다.
- 캡슐화된 패킷은 물리 네트워크를 통해 Node 2로 전달됩니다.
- Node 2는 캡슐화된 패킷을 수신하고, CNI 플러그인을 통해 원본 패킷을 추출합니다.
- 추출된 원본 패킷은 Node 2의 브리지를 거쳐 최종 목적지인 Pod B의 네트워크 인터페이스 (veth)로 전달됩니다.
- Pod B는 패킷을 수신합니다.
CNI 플러그인은 터널링을 통해 물리 네트워크 위에 가상의 플랫 네트워크를 구축하여, Pod들이 서로 다른 Node에 있더라도 직접 통신하는 것처럼 느끼게 합니다.

3. Pod와 Service 간 통신
앞선 두 경우는 Pod의 IP 주소를 알고 있다는 전제 하에 작동합니다. 하지만 Pod는 생성 및 삭제가 빈번하며, 그때마다 IP 주소가 변경될 수 있습니다. 이러한 동적인 환경에서 안정적인 통신을 위해 쿠버네티스는 Service라는 추상화 개념을 도입했습니다.
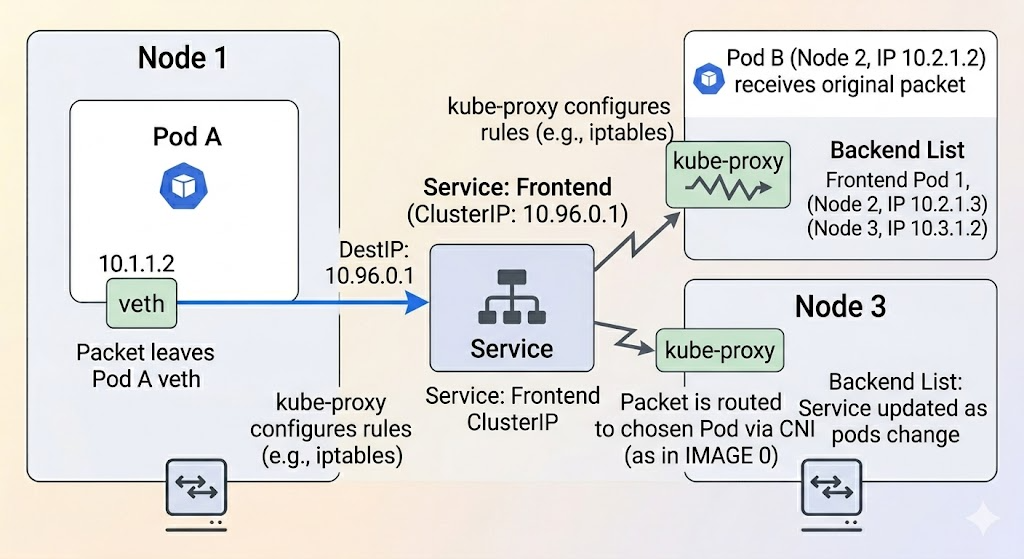
Service는 논리적인 Pod 집합에 대한 고정된 IP 주소 (Cluster IP)와 DNS 이름을 제공합니다. Pod들은 Service의 IP 주소를 통해 목표 Pod 집합에 접근할 수 있으며, 쿠버네티스는 로드 밸런싱을 통해 트래픽을 실제 Pod 중 하나로 전달합니다. 이 과정에는 kube-proxy라는 컴포넌트가 핵심적인 역할을 합니다.
작동 방식:
- 클라이언트 Pod (Pod A)가 프론트엔드 애플리케이션에 접근하기 위해 Frontend Service의 Cluster IP (10.96.0.1)로 요청을 보냅니다.
- 이 요청 패킷은 Node의 네트워크 인터페이스를 거쳐 kube-proxy가 관리하는 네트워킹 규칙 (예: iptables 또는 IPVS)에 의해 가로채집니다.
- kube-proxy 규칙은 패킷의 목적지 IP 주소를 Cluster IP에서 실제 백엔드 Pod 중 하나의 IP 주소 (예: 10.2.1.2)로 DNAT (Destination NAT) 합니다. 이때 로드 밸런싱 알고리즘이 사용됩니다.
- DNAT 된 패킷은 이제 일반적인 Pod 간 통신 과정 (동일 Node 또는 다른 Node 간 통신)을 통해 최종 목적지 Pod (Frontend Pod 1)로 전달됩니다.
- Frontend Pod 1은 패킷을 수신하고 처리합니다. 응답 패킷은 다시 반대 과정을 거쳐 Pod A로 전달됩니다.
이 과정을 통해 클라이언트 Pod는 백엔드 Pod의 개별 IP 주소를 알 필요 없이 Service의 고정된 IP 주소만을 사용하여 안정적으로 통신할 수 있습니다.
Hands-on: Pod 간 통신 테스트
이제 간단한 테스트를 통해 Pod 간 통신을 직접 확인해보겠습니다.
환경:
- 쿠버네티스 클러스터 (CNI 플러그인 설치 완료)
- kubectl 도구
1. 테스트용 Pod 생성
두 개의 간단한 Pod를 생성합니다. 하나는 웹 서버 역할을 하는 web-server Pod이고, 다른 하나는 web-server에 접근을 시도할 client-pod입니다.
# web-server.yaml
apiVersion: v1
kind: Pod
metadata:
name: web-server
labels:
app: web
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
# client-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: client-pod
spec:
containers:
- name: alpine
image: alpine:latest
command: ["/bin/sh", "-c", "sleep 3600"]
kubectl apply -f web-server.yaml 및 kubectl apply -f client-pod.yaml 명령어로 Pod를 생성합니다.
2. Pod IP 확인
생성된 Pod들의 IP 주소를 확인합니다.
kubectl get pods -o wide
출력 결과에서 web-server와 client-pod의 IP 주소를 메모해둡니다. (예: web-server: 10.1.1.2, client-pod: 10.1.1.3)
3. 통신 테스트
client-pod에 접속하여 web-server로 curl 요청을 보냅니다.
kubectl exec -it client-pod -- curl <web-server-ip>
정상적으로 통신이 된다면 Nginx의 기본 환영 페이지 소스가 출력될 것입니다.
테스트 결과 및 분석:
이 간단한 테스트를 통해 서로 다른 Pod들이 고유한 IP 주소를 사용하여 직접 통신할 수 있음을 확인했습니다. 이것이 쿠버네티스 플랫 네트워킹의 기초이며, 마이크로서비스 간 통신의 기반이 됩니다.
마치며: 쿠버네티스 네트워킹의 인사이트
오늘 우리는 쿠버네티스에서 Pod 간 통신이 어떻게 이루어지는지, 동일 Node와 다른 Node 간의 차이점, 그리고 Service와 kube-proxy의 역할까지 알아보았습니다.
쿠버네티스 네트워킹은 플랫 네트워킹이라는 단순한 목표를 지향하지만, 그 이면에는 CNI 플러그인, 터널링, iptables, DNAT 등 다양한 기술들이 복잡하게 작용하고 있습니다. 이러한 동작 원리를 이해하는 것은 다음과 같은 측면에서 큰 도움이 됩니다.
- 네트워크 문제 해결: 통신 장애 발생 시 패킷의 흐름을 추적하고 문제의 원인을 빠르고 정확하게 파악할 수 있습니다.
- 성능 최적화: CNI 플러그인의 특성과 노드 간 네트워크 환경을 고려하여 애플리케이션의 네트워크 성능을 최적화할 수 있습니다.
- 보안 강화: 네트워크 정책을 통해 Pod 간 통신을 세밀하게 제어하고 클러스터 보안을 강화할 수 있습니다.
쿠버네티스 네트워킹은 계속해서 발전하고 있으며, Cilium과 같은 최신 CNI 플러그인은 eBPF 기술을 활용하여 더욱 효율적이고 강력한 기능을 제공하고 있습니다. 앞으로도 쿠버네티스 네트워킹 기술에 지속적인 관심을 가지고 학습하는 것이 중요합니다.
이 글이 쿠버네티스 네트워킹에 대한 이해를 넓히는 데 도움이 되기를 바랍니다.
'DevOps > Kubernetes' 카테고리의 다른 글
| [k8s] 쿠버네티스 스토리지, 어디서부터 시작해야 할까? (PVC, PV, StorageClass, 그리고 CSI) (0) | 2026.04.01 |
|---|---|
| [kubernetes] 쿠버네티스의 핵심 구성요소 완벽 이해: kube-system, api-server, etcd (0) | 2026.03.25 |
| [kubernetes] 쿠버네티스 논리적 공간 관리 (멀티테넌시) 네임스페이스 (0) | 2026.03.22 |
| [kubernetes] 쿠버네티스 배포 전략 완벽 가이드: 롤링 업데이트부터 카나리 배포까지 (0) | 2026.03.18 |
| [k8s] 외부 접속은 왜 Ingress일까? 쿠버네티스 인/아웃바운드 트래픽 총정리 (0) | 2026.03.15 |

댓글